User Typesets
Files
These are the typesets provided by you. Ypu need to provide 2 files
- A CSV file with data
- A manifest file describing the Typeset
Example: pizzas Typeset
The CSV File: pizzas.csv
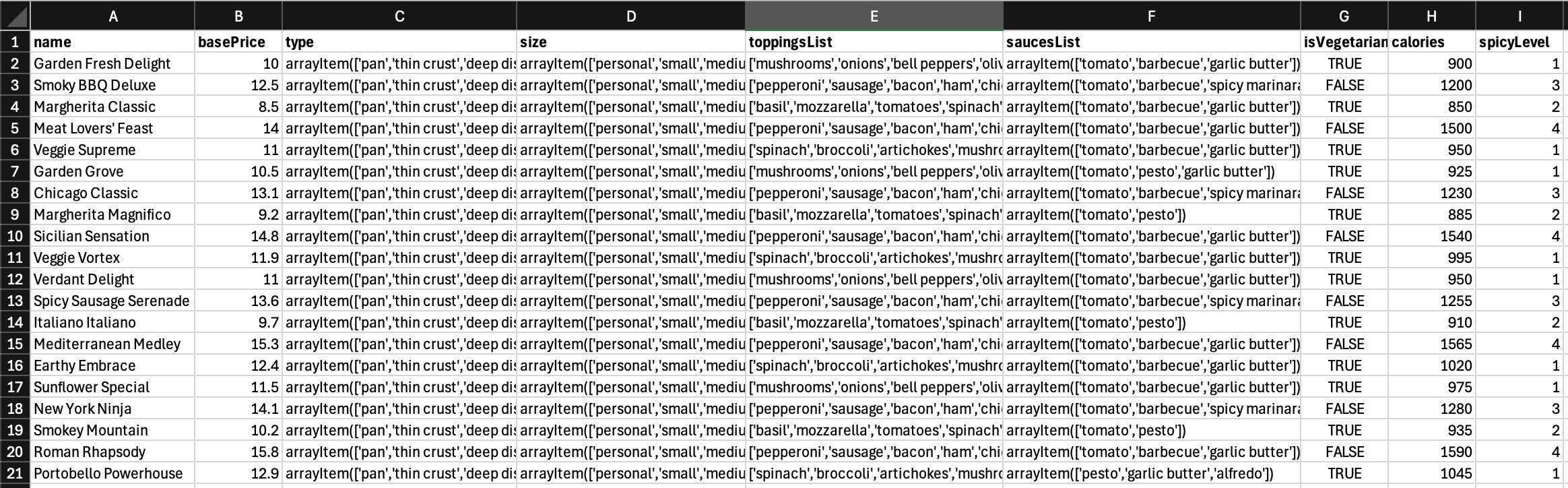 Lets take a look at the header and the first row of data:
Lets take a look at the header and the first row of data:
name,basePrice,type,size,toppingsList,saucesList,isVegetarian,calories,spicyLevel
Garden Fresh Delight,10.0,"arrayItem(['pan','thin crust','deep dish','stuffed crust'])","arrayItem(['personal','small','medium','large','extra large'])","['mushrooms','onions','bell peppers','olives','spinach','artichokes','broccoli','tomatoes','zucchini','corn']","arrayItem(['tomato','barbecue','garlic butter'])",True,900,1
- Enclose strings with commas in them in quotes
- The CSV file is not just data alone, it can also have Expressions which include Functions
The manifest file: pizzas.manifest.json
{
"name": "pizzas",
"provider": "acme",
"description": "Different types of pizzas",
"version": "1.0",
"date": "2024-10-21",
"related": true,
"file": "pizzas.csv"
}
- The typeset will be displayed as name.provider
- related: Data is correlated data
- file: The CSV file
Place both the above files in LocalStore/SyntheticData/UserTypes
Install this Typeset
This is done from the Plugins option in the Left Navigation Bar
When you click Install, the following happens:
- The manifest file is read and stored in the Capella DataStudio store
- The CSV file is copied over to homeDirectory/.capds/synthTypesets
- The CSV file is not stored in Capella DataStudio store
Use the Typeset
After installing, the Schema Builder will show this Typeset in the Type Dialog box.
User Typeset Working
Lets take the example of the above schema. When a document is generated, the following happens:
- One random row is read from the file
- If the file is less than 20 MB, the entire file is cached for performance
- If the file is more than 20 MB, the random row is read from the disk.
- The row is cached in a row-cache
- The fields are then read from this row-cache
- Once any field is read, that field is nulled in the row-cache
- If the field is null, the entire row-cache is invalidated and a new random row is read
This means
- The fields are read from the row cache and for a given document, the data is correlated.
- Each document starts with a new row-cache.
Now, lets look at the row itself. Lets consider one random row:
Garden Fresh Delight,10.0,"arrayItem(['pan','thin crust','deep dish','stuffed crust'])","arrayItem(['personal','small','medium','large','extra large'])","['mushrooms','onions','bell peppers','olives','spinach','artichokes','broccoli','tomatoes','zucchini','corn']","arrayItem(['tomato','barbecue','garlic butter'])",True,900,1
Now, the pizzas.name is straight forward and tge value is Garden Fresh Delight
pizzas.type is actually: arrayItem(['pan','thin crust','deep dish','stuffed crust'])
- This actually outputs: thin crust (for example) So, what happens is:
- The row field is read
- It is passed to an Expressions Evaluator, irrespective of what it contains
- In above example, it is a function, arrayItem which takes in an array and emits one random item from the array.
User Typesets are seed data, used to generate a huge amount of Synthetic data.
You can make this data as realistic as possible. In the pizzas example, the price, in USD is very realistic.
Expressions in the CSV file, make it completely customizable.