Expressions
Expressions are a powerful way of customizing the schema. How do they work?
- Expressions are just strings
- They can have embedded references (enclosed in %%) and functions
Example
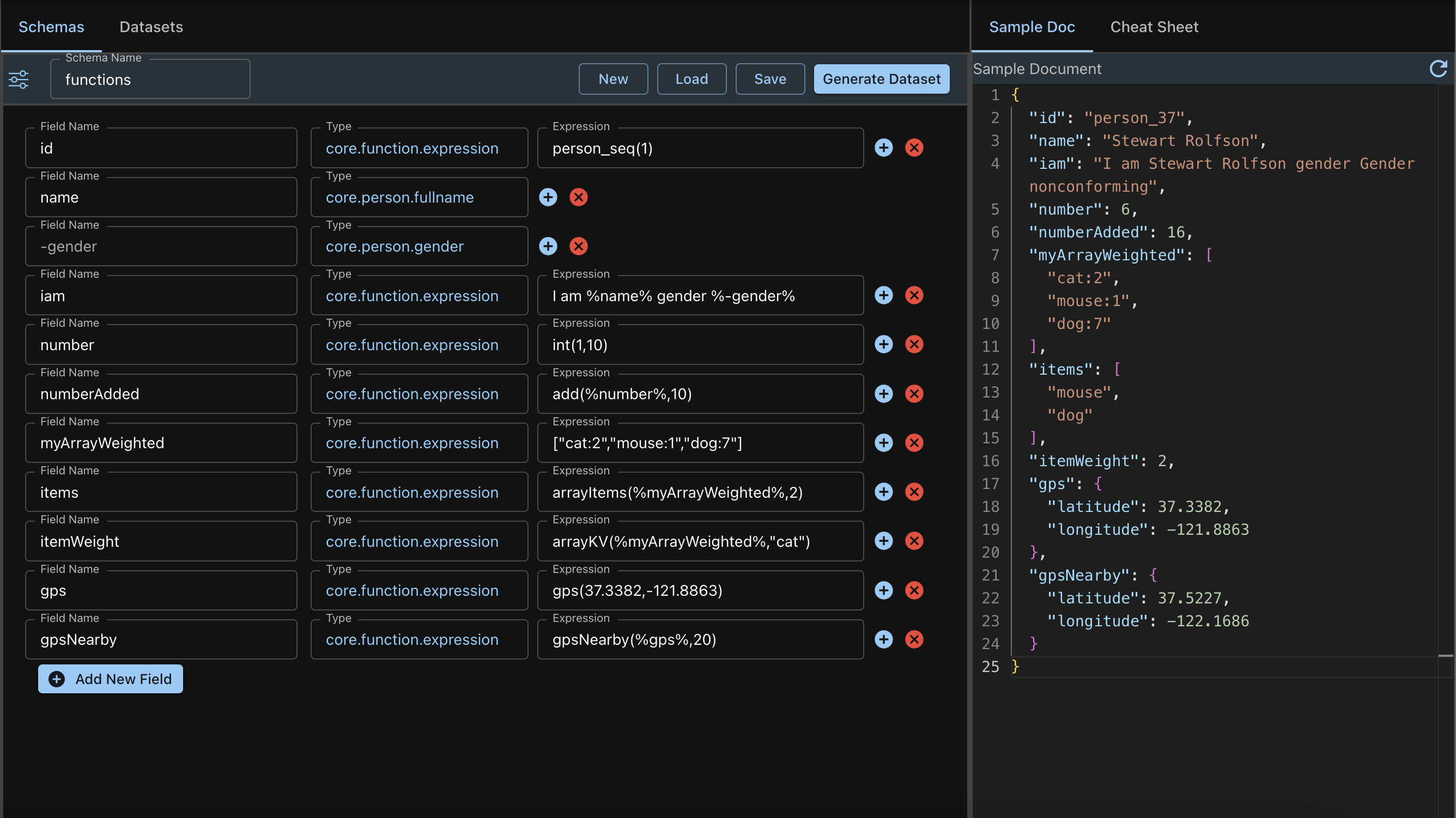 Let's examine 3 fields with Expressions:
Let's examine 3 fields with Expressions:
- id: person_seq(1)
- Expression has an embedded function, seq(1)
- The function is evaluated and the output of the function, which is an int, replaced in the string
- The output then is: person_37
- iam: Iam %name% gender %-gender%
- Expression has 2 embedded references
- The reference is to fields, name and *-gender *which have been previously declared and evaluated
- These values are replaced in the string
- numberAdded: add(%number%,10)
- Expression just has a function add with an embedded reference
- The reference is first evaluated and its value replaced in the function
- The function is then executed
- The output is returned
Document and Expression architecture
From the above, we can see how Expressions work. But first, let's see how the document is built.
- The document is built, top down, row by row.
- We always have a partial document at every row stage.
- First, the expression is a string
- It goes to an Expression Evaluator
- The partial document, with its fields and values is supplied to the evaluator.
- This means, the previous fields and their evaluated values are now available.
- The partial document, with its fields and values is supplied to the evaluator.
- The string is then examined for references
- References are field names, previously used, and their values, from the partial document.
- References are replaced by the values
- This means that references can also be inside of functions
- The string is then examined for functions
- The functions are then executed and their values are replaced in the partial document.
- The Evaluator finally returns back the output.
Functions
| Type | Example | Output | Notes |
|---|---|---|---|
| int(min,max) | int(1,10) | 6 | |
| float(min,max) | float(1.234,10.587) | 5.824 | decimals taken from input |
| float(min,max,dec) | float(1,10,2) | 5.82 | decimals specified |
| normal(mean,stddev,dec) | normal(50,10,3) | 56.48 | normal distribution |
| bool() | bool() | false | 50/50 chance |
| bool(bias) | bool(0.8) | true | weighted to true 0 to 1.0 |
| date(from,to) | date(01/01/2024,12/31/2024) | "02/02/2024" | configurable output pattern |
| time(from,to) | time(08:00 am, 5:00 pm) | "08:47 AM" | configurable output pattern |
| arrayItem(array) | arrayItem(["cat","mouse","dog"]) | "cat" | equally weighted |
| arrayItem(array) | arrayItem(["cat:2","mouse:1","dog:7"]) | "dog" | weighted array |
| arrayItems(array,length) | arrayItems(["cat","mouse","dog"],2) | ["cat","mouse"] | equally weighted |
| arrayItems(array,length) | arrayItems(["cat:2","mouse:1","dog:7"]) | ["cat","dog"] | weighted array |
| arrayKV(array,field) | arrayKV(["cat:2","mouse:1","dog:7"],"cat") | 2 | value of field |
| gps(latitude,longitude) | gps(37.3382,-121.8863) | gpsObject | returns object |
| gpsNearby(gps,radius) | gpsNearby(%gps%,20) | gpsObject | returns object, generally use reference, radius in miles |
| seq(startNumber) | seq(1000) | 1030 | generally used like: store_seq(1) |
| uuid() | uuid() | "e46b493a-ac90-4258-ad69-ec4bd94ebf59" | uuid |
| add(num1,num2) | add(1.23,3.45) | 4.68 | pass numbers |
| subtract(num1,num2) | subtract(1.23,3.45) | -2.22 | pass numbers |
| multiply(num1,num2) | multiply(1.23,3.45) | 4.24 | pass numbers |
| percent(numerator,denominator) | percent(1.23,3.45) | "35.65%" | outputs string |
| accumulate(nums,name) | accumulate(%orders.subTotal%,sale) | 1304.84 | accumulate within JSON Array |
Notes
gpsObject Example
{
"latitude": 37.3382,
"longitude": -121.8863
}