Overview
- A Data Set is a bundle of one or more CSV/JSON data and optional indexes and a manifest file describing the data as well as instructions which scope to install them in.
- Couchbase offers a set of curated Data Sets in the Public Store (more on this in the next section).
- You can create your own Data Set and store it in:
- Your Local Store: This is on your Mac and private to you
- A shared Cloud Store: To colloborate with your team
Example Data Set
Full Local Repository
~/Documents/MyRepository
├── Backups
│ ├── travel-sample
│ │ ├── 2023-10-05T09_43_34.506946-07_00
│ │ ├── 22023-10-24T09_48_26.419267-07_00
│ │ ├── 2024-01-20T12_39_35.08943-08_00
│ │ │ ├── cluster-config.json
│ │ │ ├── plan.json
│ │ │ ├── travel-sample-090c5855f34364b6eaf63d18675fb1d7
│ │ │ │ ├── gsi.json
│ │ │ │ ├── gsi.metadata.json
│ │ │ │ ├── data
│ │ │ │ │ ├── *.*
│ │ │ │ ├── ranges
│ │ │ │ │ ├── *.*
│ │ ├── README.md
│ │ ├── backup-meta.json
│ ├── views
│ ├── model
│ ├── index.js
├── Datasets
│ ├── music
│ │ ├── couchmusic2-countries.json.zip
│ │ ├── couchmusic2-playlists-1.json.zip
│ │ ├── couchmusic2-playlists-2.json.zip
│ │ ├── couchmusic2-subregions.json.zip
│ │ ├── couchmusic2-tracks.json.zip
│ │ ├── couchmusic2-userprofiles.json.zip
│ │ ├── manifest.json
│ ├── movies
├── Favorites
│ ├── travel-sample
│ │ ├── inventory
│ │ │ ├── 1.sql
│ │ │ ├── 2.sql
The Datasets section
- Folder: Each Dataset must be in its own folder. The name is not displayed
- Files: These can be json/csv/tsv files. They must all be of the same type. They must be zipped.
- You must have a manifest.json file.
manifest.json
Here is an example of the file for the music dataset
{
"name": "Couch Music",
"title": "Music",
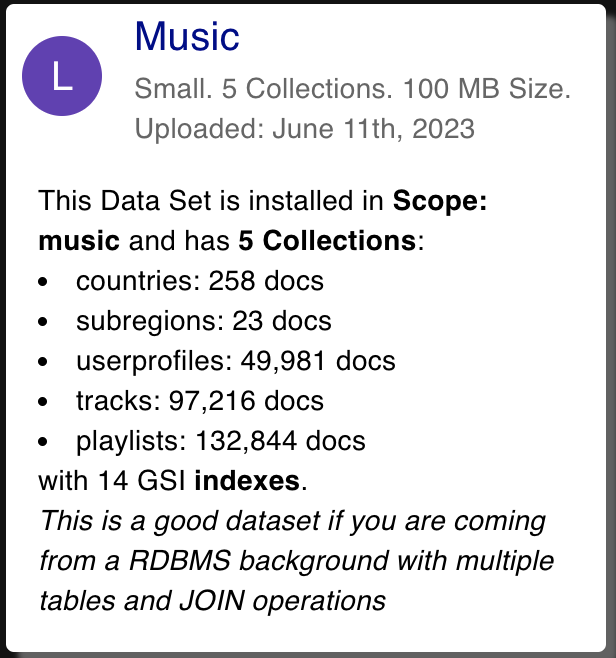
"subtitle": "Small. 5 Collections. 100 MB Size. Uploaded: June 11th, 2023",
"description": "This Data Set is installed in **Scope: music** and has **5 Collections**: --countries: 258 docs-- --subregions: 23 docs-- --userprofiles: 49,981 docs-- --tracks: 97,216 docs-- --playlists: 132,844 docs-- with 14 GSI **indexes**. <br>*This is a good dataset if you are coming from a RDBMS background with multiple tables and JOIN operations*",
"scope": "music",
"fileType": "json",
"formatType": "list",
"files": [
{
"collection": "countries",
"key": "country::%countryCode%",
"docs": "couchmusic2-countries.json.zip",
"indexes": [
"CREATE INDEX country_code ON countries (countryCode)",
"CREATE INDEX country_region_number ON countries (`region-number`)"
]
},
{
"collection": "subregions",
"key": "sub-region::%region-number%",
"docs": "couchmusic2-subregions.json.zip",
"indexes": ["CREATE INDEX region ON subregions (region)"]
},
{
"collection": "userprofiles",
"key": "userprofile::%username%",
"docs": "couchmusic2-userprofiles.json.zip",
"indexes": [
"CREATE INDEX userprofile_address_country_code ON userprofiles (countryCode)",
"CREATE INDEX userprofile_created ON userprofiles (created)",
"CREATE INDEX userprofile_status ON userprofiles (status)",
"CREATE INDEX userprofile_gender ON userprofiles (gender)",
"CREATE INDEX userprofile_last_name ON userprofiles (lastName)",
"CREATE INDEX userprofile_first_name ON userprofiles (firstName)"
]
},
{
"collection": "tracks",
"key": "track::%id%",
"docs": "couchmusic2-tracks.json.zip",
"indexes": [
"CREATE INDEX track_artist ON tracks (artist)",
"CREATE INDEX track_genre ON tracks (genre)",
"CREATE INDEX track_title ON tracks (title)",
"CREATE INDEX track_avg_rating ON tracks (avg_rating)"
]
},
{
"collection": "playlists",
"key": "playlist::%id%",
"docs": "couchmusic2-playlists-1.json.zip"
},
{
"collection": "playlists",
"key": "playlist::%id%",
"docs": "couchmusic2-playlists-2.json.zip"
},
{
"collection": "playlists",
"key": "playlist::%id%",
"docs": "couchmusic2-playlists-3.json.zip",
"indexes": ["CREATE INDEX playlist_owner ON playlists (owner.username)"]
}
]
}
Please take a look at the details to be provided. This will display on the UI like so:
- Clicking this will import this Dataset into your Active Database
- It will automatically create the required Scope and Collections
- It will automatically create and build the indexes